Vor ein paar Wochen konnten wir einen Einblick in die Tätigkeiten und Erfahrungen von Julian 1 aus dem Frontend-Team bekommen. Hauptsächlich befinde ich mich mit Jonas, Julian 2 und Steffen im Backend-Team. Wie die Überschrift es jedoch schon vermuten lässt, arbeite ich auch teamübergreifend.
Als es beim MS-Hack um die Rollenverteilung für die nächsten 36h ging, habe ich mich direkt im Frontend-Team gesehen. Diese Entscheidung beruhte auf verschiedenen Faktoren: Ich habe viel praktische Erfahrung im Programmieren, jedoch kaum welche im Bereich Frontend. Dazu lag der Fokus beim MS-Hack auf einer guten Idee (welche bereits vorlag) und einer überzeugenden UI, die keiner Datenbank oder aufwändigen Logik aus dem Backend bedarf. Hierzu hatte Julian 1 bereits ausführlich berichtet.
Nach dem MS-Hack haben wir uns als Team Gedanken zu dem aktuellen Stand gemacht und wir wir das Team für das Semester ausrichten wollen. Für uns alle war direkt klar: Feste Teams wollen wir nicht. Jedes Mitglied kann zu jeder Zeit das Team wechseln und somit auch schnell neue Erfahrungen sammeln. Wir haben unsere Kenntnisse und Interessen offengelegt und uns auf die drei Teams „Frontend“, „Backend“ und „Recherche / Data Analysis“ aufgeteilt. Hier habe ich mich zunächst für das Backend entschieden. Schon nach den ersten Minuten im Team gab es kleine Diskussionen über die Anforderungen an einen geeigneten Algorithmus. Der erste Schritt nach der Anforderungsanalyse war typisch für Bilderbuch-Informatiker: Wir haben im Internet nach dem perfekten Algorithmus gesucht. Schnell herrschte Euphorie, denn der C4.5 Algorithmus schien die perfekte Lösung zu sein. Dieser deckte – zum damaligen Zeitpunkt – unsere Anforderungen ab. Nach den ersten erfolgreichen Tests, haben wir im wöchentlichen Jour-fixe sehr für diesen Algorithmus geschwärmt – vergeblich. Obwohl dieser unsere ersten Anforderungen abgedeckt hat, wurde uns schnell klar, dass wir diese noch nicht detailliert genug definiert und viele wichtige Aspekte vergessen hatten. Zu diesem Zeitpunkt haben wir uns im Backend-Team erneut aufgeteilt.
Abgekoppelt vom Algorithmus, kümmere ich mich seitdem um die Entwicklung der API. In diesem Bereich bringe ich bereits Erfahrungen mit und konnte so in enger Abstimmung zwischen Frontend- und Algorithmus-Team die API entwickeln. Für die API existieren sehr viele Lösungen und wir mussten uns für eine dieser Entscheiden. Zuallererst mussten wir uns überlegen wie die Informationen an das Frontend übertragen werden sollen. Der erste Ansatz war eine einmalige Übertragung aller Knoten des Baumes an das Frontend. Bei dieser Wahl konnten wir uns für eine REST API entscheiden. Wo liegt hier der Vorteil? Das Frontend sagt dem Backend nach definierter Logik, welche Informationen es benötigt und das Backend schickt diese Informationen. Sowohl vor als auch nach der Anfrage besteht zwischen beiden keine Verbindung. Dies erlaubt eine strikte Trennung von Frontend und Backend, was die Entwicklung beschleunigt. Wir haben uns für Flask entschieden, um genau zu sein für Flask-RESTful. Der Unterschied zum normalen Flask ist lediglich der objektorientierte Ansatz. Flask ist ein kleines Framework und sehr anpassungsfähig.
Was musste in der API alles beachtet werden?
Nach unserem damaligen Stand war das ganze sehr simple: Der User startet auf der Website den Dialog (zB. https://localhost/dialog) und im Hintergrund fragt das Frontend das Backend nach dem Baum (zB. https://localhost/api/baum). Das Backend antwortet mit einer JSON-Datei, in welcher jeder mögliche Weg des Fragenkataloges abgebildet ist und das Frontend bildet die Fragen nach dem jeweiligen Pfad ab. Eine solche API ist wirklich schnell aufgesetzt und da ich aus diesem Grund vor dem Algorithmus-Team fertig war, widmete ich mich einem neuen Thema: MongoDB hosten. Dank Sven haben wir uns nicht für eine klassische SQL-Datenbank entschieden, sondern für MongoDB. Dies ist eine nicht-relationale Datenbank und die Operationen auf dieser unterscheiden sich grundlegend. Wir sind Bleeding-edge-user und wagen uns an diese kritisch betrachtete Datenbank heran. Im Team haben wir kurz besprochen wie wir das Projekt hosten wollen und es war direkt klar, dass wir Docker nutzen wollen. Über Docker kann man Projekte in Containern laufen lassen und vorher feste Regeln festlegen, damit ein Projekt auf jedem PC/Server identisch läuft – sehr praktisch. Auch hier konnte ich meine Vorerfahrung nutzen und die Datenbank innerhalb von fünf Minuten aufsetzen. Leider stellten sich nach und nach mehr Hürden in den Weg…
Da Docker auf jedem System die gleichen Voraussetzungen schafft, habe ich MongoDB auf meinem Mac aufgesetzt und mich in diese eingearbeitet. Das war kein Problem und ich konnte meinen Teamkollegen zeigen, wie toll Docker doch wäre. Nun zu unserem Server. Dieser wurde uns von der Uni zur Verfügung gestellt. Wir haben uns für das vielseitige Ubuntu entschieden, welches über eine VM läuft. Dies stellte unser erstes Problem dar. Die neueste Version von MongoDB (zu diesem Zeitpunkt Version 6.0) war problemlos mit Docker auf dem Mac kompatibel, jedoch nicht mit unserem Server, da der Prozessor gewisse Features nicht an die VM weitergibt. Die Lösung des Problems liegt in Version 4.4.6, welche älter ist, jedoch unsere Anforderungen mehr als genug abdeckt. Nun läuft die Datenbank auf dem Server und man kann Daten hinzufügen – vorausgesetzt man ist per SSH verbunden. Nach vielen Versuchen die Firewall korrekt zu konfigurieren stellte sich heraus, wir können nicht selbst die Ports freigeben. Nach kurzer Absprache mit Sysad des WI-Instituts, war das Problem vergessen und wir konnten die Datenbank aktiv nutzen. Aktuell kann man im Uni-Netz auf die Datenbank zugreifen. Dies ist beim Entwicklungsprozess der Fall. Sobald das Projekt öffentlich ist, wird die Datenbank nur noch durch die API zu erreichen sein, damit wir die Sicherheit erhöhen.
Nachdem alles eingerichtet war, näherte sich der Algorithmus dem Ende zu. Dieser war noch nicht ganz fertig und dennoch waren Probleme absehbar. Die Datenmenge betrug 400MB. Für einen Websitebesuch ist diese Menge (heutzutage 🙂) niemandem zumutbar. Also Planänderung: Der Algorithmus speichert die einzelnen Knoten jeweils als ein eigenes Dokument in der Datenbank und das Frontend fragt nach jeder Frage im Dialog das Backend nach der nächsten Frage. Auch hier kann die REST API ihren Zweck erfüllen. Jeder Knoten in der Datenbank enthält eine Frage und die zugehörigen Antworten, welche jeweils die ID der nächsten Frage enthalten. Wird im Frontend eine Antwort ausgewählt, so wird im Body der HTTP Anfrage die ID an das Backend geschickt und dieses weiß direkt, welcher Knoten als nächstes geschickt werden muss. Dieser Ansatz beinhaltet sehr viele Anfragen, ist jedoch deutlich datensparsamer wenn man aus der Sicht des Clients schaut.

Da nun das Backend funktionstüchtig ist und vor der Zwischenpräsentation krankheitsbedingt das Frontend-Team nicht ganz leistungsfähig ist, wechseln fast alle aus dem Backend-Team zum Frontend.
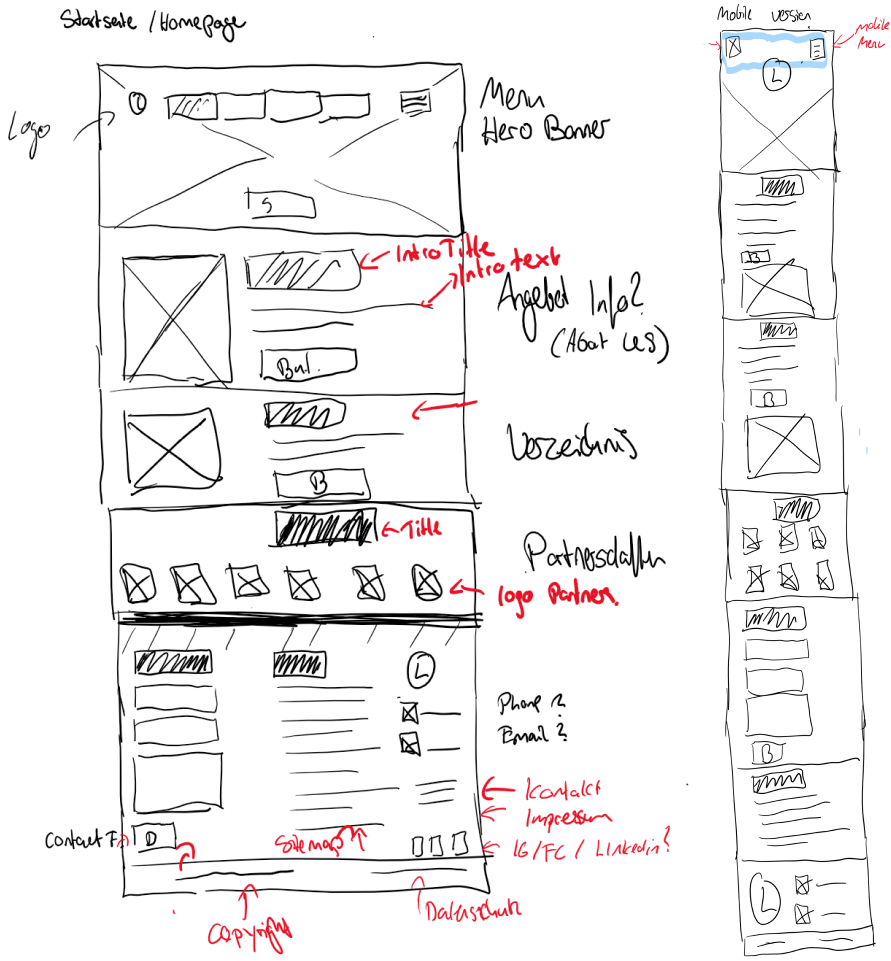
Ich habe mich für die Implementierung der Startseite und der Navigationsleiste gemeldet und dies Mithilfe unserer Technologien ReactJS und MUI umgesetzt. Bei der Zwischenpräsentation war das Ziel eine funktionstüchtige Web-App im Desktop-Browser zu präsentieren. Responsiveness (also die Anpassungsfähigkeit auf alle Bildschirmgrößen) ist hier noch unwichtig und wird zum Ende des Projekts vollständig umgesetzt sein. Das Entwickeln der Startseite hat sich wie der MS-Hack (in ein bisschen länger) angefühlt, da wir deutlich weniger als eine Woche Zeit hatten. Als klug hat sich die Deadline zwei Tage vor der Präsentation herausgestellt, da wir diese verfehlt haben. Wir wollen uns nicht ausmalen, wie das Verfehlen der Zwischenpräsentation als Deadline geendet hätte.
Nun zum Tag der Zwischenpräsentation. Diese soll um 16:00 Uhr stattfinden. Es ist 14:00 Uhr und so langsam sind alle fertig, die Website, der Algorithmus und die Datenbank sind alle in Symbiose – theoretisch zumindest. Bisher ist zu dem Zeitpunkt die Datenbank online. Der Rest läuft nur auf unseren Rechnern. Also gilt es nun das gesamte Projekt innerhalb kürzester Zeit in drei Docker-Container zu verpacken und diese alle miteinander zu vernetzen. Als hilfreich hat sich Docker Compose erwiesen. Dieses Tool kann verschiedene Dockerfiles kombinieren. Dank Docker konnten wir unseren Sozialkompass an diesem Tag das erste mal live auf einer Website betrachten und vollständig den Dialog mit einem belastbaren Ergebnis testen und in unsere Präsentation einbinden.

Nun befinden wir uns in der Gegenwart. Über Weihnachten gönnen wir uns eine kleine Pause und werden in den Ferien den Code ein wenig überarbeiten und kleinere Bug-fixes implementieren. Im neuen Jahr werde ich voraussichtlich wieder an der API arbeiten und diese für das Admin-Interface vorbereiten, damit die Daten in der Datenbank von einer dritten Person bearbeitet werden kann.
Ich hoffe ich konnte euch einen guten Einblick in meine Arbeit und Vorgehensweise gewähren.
Euer Ole